tg-me.com/codeby_sec/9046
Last Update:
Инструмент на Python, разработанный для автоматизации сбора информации и представляет собой веб-краулер, который извлекает данные с веб-сайтов. Имеет настраиваемую глубину сканирования, поддерживает различные фильтры и позволяет сохранять данные в удобном формате.
Photon начинает работу с корневого URL и следует по всем обнаруженным ссылкам до заданной глубины. Затем анализирует HTML-код каждой страницы, используя библиотеку BeautifulSoup и регулярные выражения и извлекает данные в структурированном виде.
git clone https://github.com/s0md3v/Photon.git
cd Photon
pip install -r requirements.txt
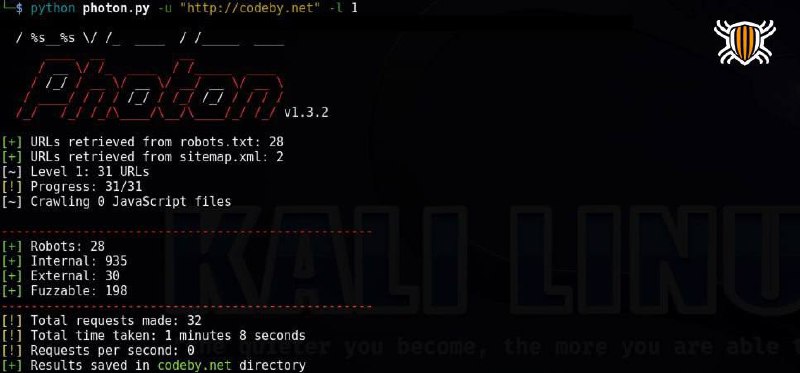
Сканирование заданного URL с глубиной поиска 2:
python3 photon.py -u https://example.com -l 2
Поддерживает следующие опции:
--timeout: количество секунд, в течение которых следует ожидать, прежде чем считать, что запрос HTTP(S) не выполнен;
--delay: количество секунд ожидания между каждым запросом;
--threads: указание количества одновременных запросов;
--level: ограничение на глубину рекурсии при сканировании;
--cookies, --user-agent: добавление Cookie в каждый HTTP-запрос, пользовательские агенты;
--exclude: URL, соответствующие указанному регулярному выражению, не будут сканироваться и не будут отображаться в результатах поиска;
--seeds: пользовательские начальные URL;
--only-urls: не извлекаются различные файлы, сканируется только целевая страница;
--regex: указывается шаблон для извлечения строк во время сканирования;
--keys: поиск строк с высокой энтропией;
--dns: сохраняет поддомены в файле subdomains.txt, а также генерирует изображение с данными DNS целевого домена;
--wayback: извлекает архивные URL-адреса с сайта archive.org и использует их в качестве начальных.